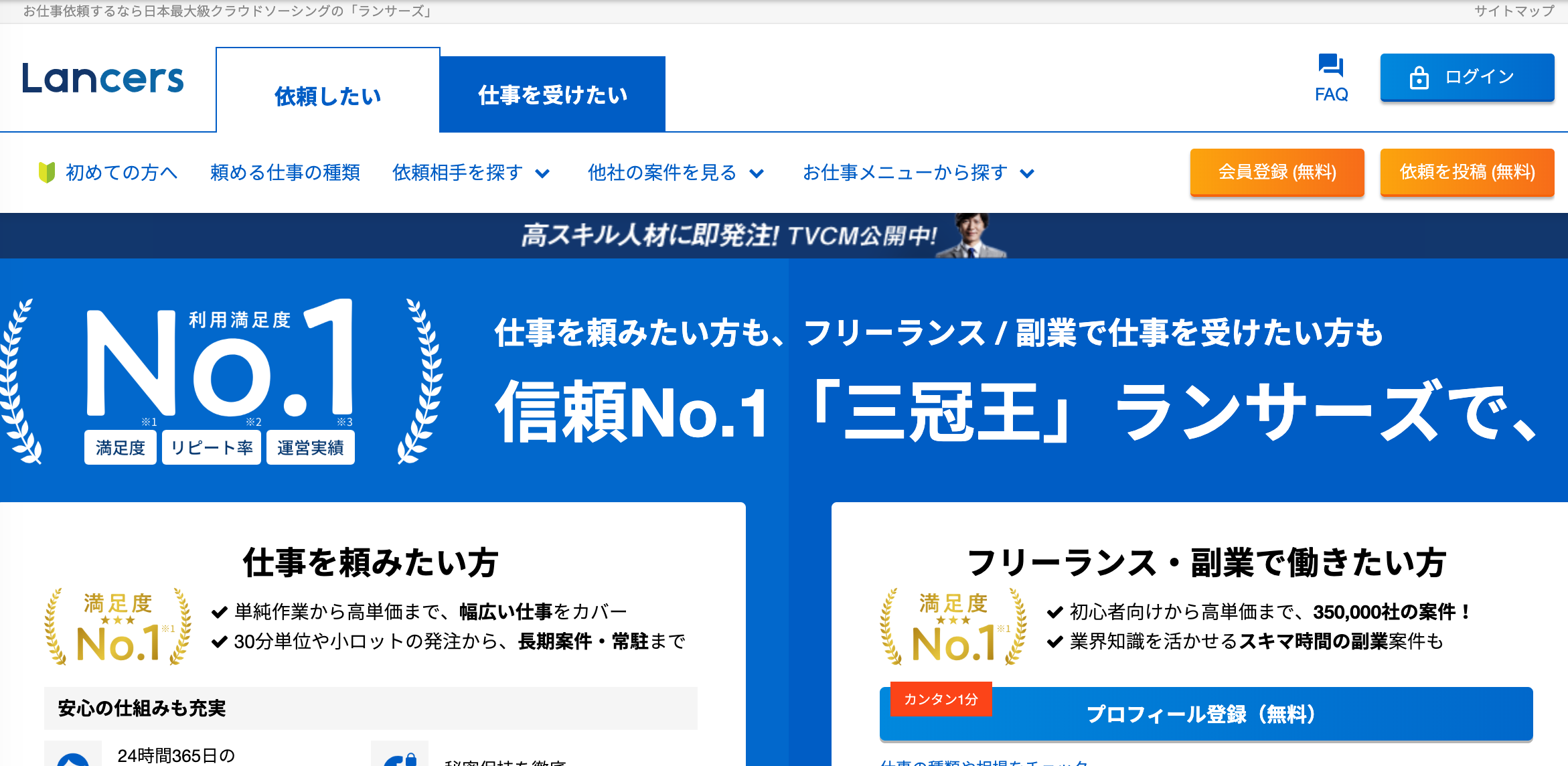
スクレイピングでランサーズから、自分が希望する案件を自動的に検索できるコードを作成しようと試みたのですが、requestライブラリを使用しても接続できませんでした。どうしてできないのかを検証してみました。
コンテンツ
結論から言えば
seleniumを使用する事でクローリングできました。
環境
| Mac | 10.14 |
| python | 3.7 |
| Chrome | 77.0 |
前提条件
- selenium
- chromedriver インストール済み
- beautifulsoup4 インストール済み
お課
クローリングする為にランサーズに接続してみよう
まずは試しに「ヤフー」のホームページにアクセスをしてみます。
|
1 2 3 4 5 6 7 |
#coding:utf-8 import requests, bs4 from bs4 import BeautifulSoup res = requests.get("https://www.yahoo.co.jp") res.raise_for_status() soup = bs4.BeautifulSoup(res.text,"html.parser") print(soup) |
実行!
無事接続できました。
では次に、yahoo.co.jpをlancers.jpに変えて実行してみます。
|
1 2 3 4 5 6 7 |
#coding:utf-8 import requests, bs4 from bs4 import BeautifulSoup res = requests.get("https://www.lancers.jp") res.raise_for_status() soup = bs4.BeautifulSoup(res.text,"html.parser") print(soup) |
エラーが出てしまいました。要約すると、「禁止されています」とのこと。

robots.txtでクローリングを検索
クローリングのルールについて定めたrobots.txtという仕組みがあります。SEOを頑張っているサイトには大抵ありますので、ランサーズにもこれを実行させてみます。URLのすぐ後に、robots.txtと入力して実行
https://www.lancers.jp/robots.txt
実行すると↓

詳しい事はググれば出てきますので、ざっくり要約してみます。
Crawl-delay:600 ⇨ Crawl-delayはアクセス頻度で、ページングによって何度もwww.lancers.jpにアクセス(≒ページ遷移)が発生しうる場合は600秒を守るべきですね部分に関しては「600秒時間をあけて。」という解釈になります。なので初めて接続する分には全く問題ないはず・・・。
Disallow: / ⇨ is_archiverもarchive.org_botは特定botを名指ししているので、個人が作成したbotはひっかからないと考えられる。
結論
ブラウザではアクセスできるのにpython script経由ではできない、といった場合にはrequestsの代わりにseleniumなどのシミュレーターを使ったスクレイピングが有効なのでそれを試してみる。
|
1 2 3 4 5 6 7 8 |
import time import requests,bs4 import chromedriver_binary from selenium import webdriver driver = webdriver.Chrome() driver.get("https://www.lancers.jp") soup = bs4.BeautifulSoup(driver.page_source,"html.parser") print(soup) |
これを実行すると
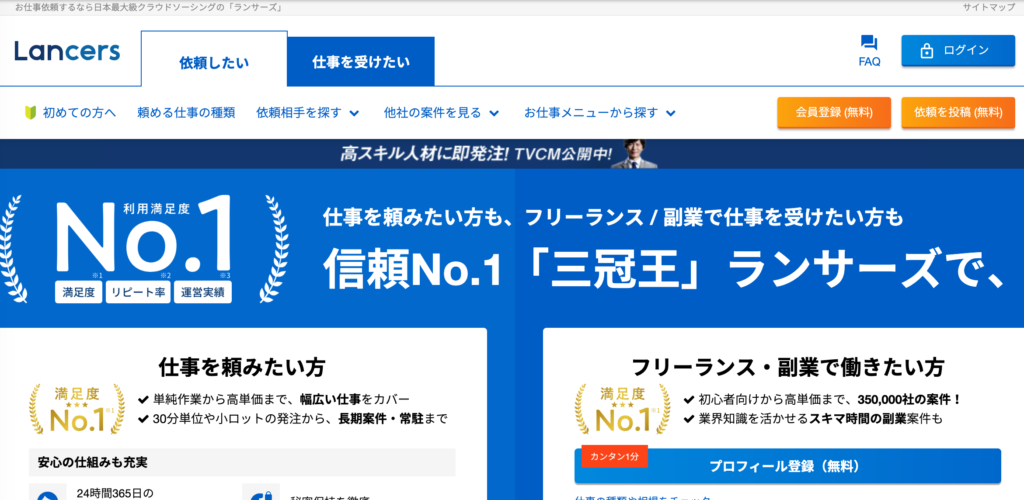
無事接続できました!
そしてURLのリンク先の要素もprintで取得できます。
スクールを利用して本格的に学ぶ
10人中9人が挫折すると言われるプログラミングを、半年間もの間頑張れ、結果、今はPythonエンジニアとして働く事ができているヒロヤンは、プログラミングスクールを利用して自ら目標を設定して講師の言う通りにひたすら打ち込んだまでです。
挫折率が高いプログラミングこそお金を払ってメンターを付けて、道を見失わないように環境を構築する必要があるのではないでしょうか。
結局一人だとどうしてもだらけてしまいます。
これはダイエットで自分一人では痩せられないけど、トレーナーを付けて否が応でもせざるを得ない環境を作ると一緒ですね。
ヒロヤンもプログラミング勉強開始直後はあれこれ悩みましたが、悩むよりも手っ取り早くスクールに登録した方が最短ルートで勉強できるのではないかと考えました。









コメントを残す